

Silizium-Intuition: Machine Learning (Teil 1/III: ML im Unternehmen)
Machen wir mal was mit KI ... die anderen tun es ja auch.

Inhalt
Machine Learning im Unternehmen
“Yet AI has been difficult for organizations to adopt because organizations have to change how they think, act and learn in order to take advantage of what it offers.”
--- Karthik Ramakrishnan
“ AI projects face unique obstacles due to their scope and popularity, misperceptions about their value, the nature of the data they touch”
-- Gardner
Reifegradmodelle bei KI Projekten

Machen Sie sich ehrlich, wie weit ist eine beliebige KI-Initiative im Unternehmen gediehen, gibt es überhaupt eine? Sofern sich ein Unternehmen für den Einsatz von KI entscheidet - und kaum eines der Unternehmen kann es sich aktuell leisten KI nicht zumindest in das strategische Kalkül aufzunehmen - stellt sich die essenzielle Frage, wie ein Unternehmen sich aufzustellen hat, um den Übergang vom singulären KI-Experiment zur effektiven Umsetzung von KI im Unternehmen zu bewerkstelligen.
Reifegradmodelle liefern eine Bewertungs- und Vergleichsbasis für Verbesserungen und sind somit Entscheidungsinstrumente zur Ermittlung von Optimierungen. Der Begriff “Reife” suggeriert in diesem Kontext, dass eine schrittweise Verbesserung bei Erreichung gewisser Fähigkeiten oder Ziele von der Start- bis zur erstrebten Endphase stattfindet. Der grundlegende Zweck von Reifegradmodellen besteht somit in der Beschreibung von Phasen und und den Pfaden zwischen ihnen.
Ausgehend vom TOE-Framework als meta-strukturellem Hilfsmittel, können die Faktoren eines Reifegradmodells systematisch erarbeitet werden:

Technological Dimension:
Reife von ML-Infrastrukturen, Datenqualität, Modellmanagement, Automatisierungsgrad (z. B. MLOps)
Passt zu technischen Metriken wie Deployment-Fähigkeit, Monitoring, Wiederverwendbarkeit von Pipelines
Organizational Dimension:
Reife der organisatorischen Strukturen, Kompetenzen, Governance, ML-Kultur
Passt zu Metriken wie Skill-Level, Change Management, Teamorganisation, Wissensmanagement
Environmental Dimension:
Externe Rahmenbedingungen: Regulierung, Marktdruck, Partnernetzwerke
Passt zu Aspekten wie DSGVO-Compliance, Branchennormen (z. B. ISO/IEC 24029 für AI), Wettbewerbseinfluss
Analog zu den CMM des Software Engineering Institute (SEI) der Carnegie Mellon Universität hat bspw. Gardner ein Reifegradmodell entwickelt, welches sich wie folgt darstellt:
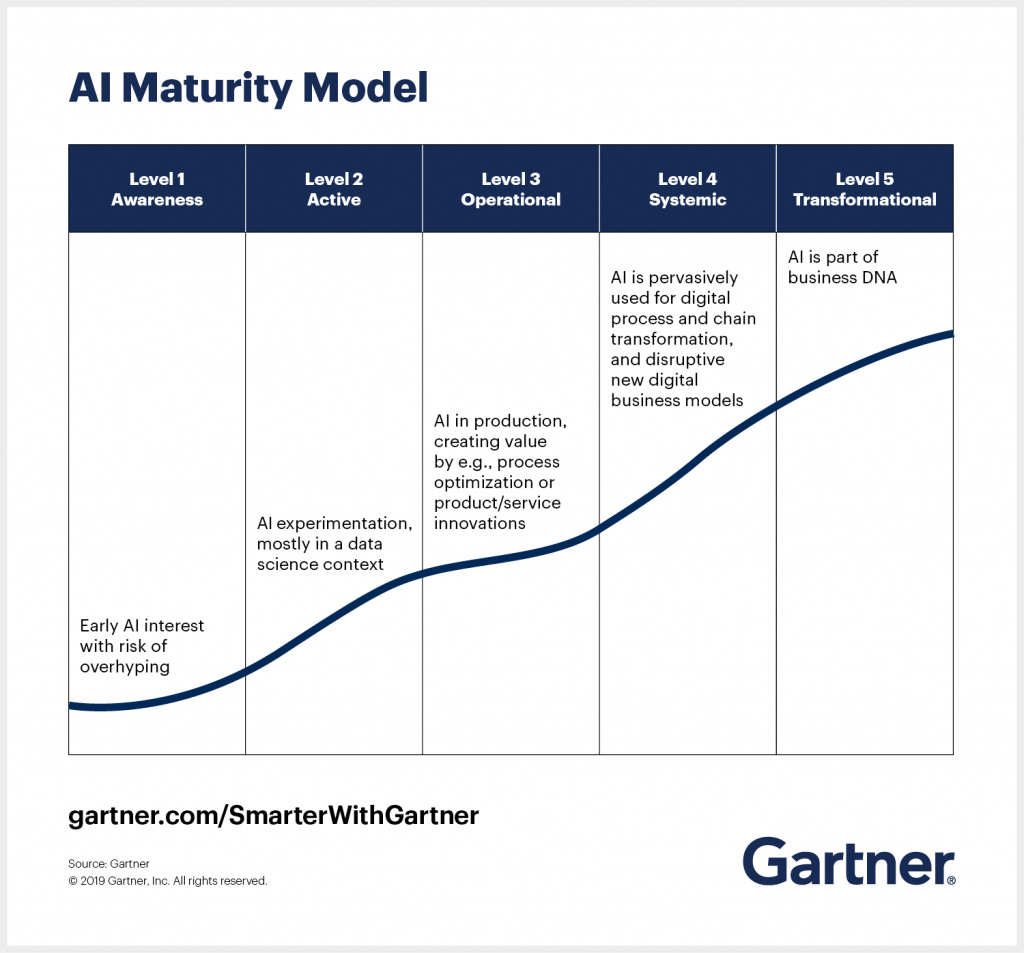
Der Level, auf dem sich das Unternehmen befindet, hat Einfluß darauf, wie erfolgversprechend das Erreichen von Projektzielen im Kontext KI / ML sein wird. Das man bei diesen Projekten weitaus mehr als nur die Stufen eines Reifegradmodells beachten muss und natürlich ein solches Projekt weitaus mehr als nur Technologie ist wird klar, wenn man sich das Reifegradmodell von Calvin Limat (Universität St. Gallen) betrachtet, welches den Reifegrad eines Unternehmens weniger als Pfad durch die einzelnen Reifegrade, sondern vielmehr in Gestaltungsdimensionen und Gestaltungsobjekte unterteilt - also eine Konkretisierung des TOE-Framework abbildet.

Hierbei sind insbesondere die Gestaltungsdimensionen hier von Interesse, die nachfolgende Tabelle wurde aus dem oben in der Fußnote genannten Dokument übernommen.

Beide Reifegradmodelle sind eher komplementär und es ist wichtig, sich im Unternehmenskontext klarzumachen, auf welcher Stufe des Modells von Gardner sich das Unternehmen aktuell befindet und ob und wie die Gestaltungsdimensionen des Modells von Calvin Limat berücksichtigt wurden oder wie sie in Zukunft berücksichtigt werden sollen.
Rahmenbedingungen eines ML-Projektes definieren
“Ohne klare Ziele führt jeder Weg dorthin”
-- unbekannt
Das ist keine uralte chinesische Weisheit, vielmehr eine oft ignorierte Tatsache. Ausgehend von den Reifegradmodellen des vorherigen Abschnitts soll in diesem Abschnitt eine mögliche Zielhierarchie für ein ML-Projekt entwickelt werden - oder zumindest eine Idee skizziert werden, welche Ziele existieren können und natürlich empfiehlt es sich die im Folgenden genannten Ziele ggf. selektiv zu handhaben und sie mit Gewichten zu versehen. Dann und nur dann kann der Projekterfolg messbar bestimmt werden.

Nehmen Sie bitte das folgende Beispiel als “Leitfaden”, um essentielle Aspekte Ihres Projektes abzudecken.








Gesetzliche Regularien und Datenschutz

Sie sind begeistert davon, dass Ihre Nutzerdaten und Bilder für jeden Anwendungsfall von Großkonzernen (und Behörden; Gruß an die ehemalige Bundesinnenministerin und den hessischen Innenminister -> HessenData, Palantir, …) zu Ihnen unbekanntem Zwecke herangezogen werden? Das dürfte fast jedem so gehen und bewegt sich oft hart am Rande der Legalität.
Sowohl Meta als auch Google (sowie andere) sammeln enorme Mengen an personenbezogenen Daten, die weit über das hinausgehen, was für die eigentliche Dienstleistung nötig ist. Google trackt z. B. Nutzerdaten über zahlreiche Plattformen hinweg und analysiert das Nutzungsverhalten über Gmail, YouTube, Maps und das Suchverhalten. Meta erfasst ebenfalls viele Informationen, darunter Freundesnetzwerke, Interaktionen, Standortdaten und Online-Verhalten.

Auch die (hessische) Polizei sammelt alles, dessen sie habhaft wird. Diese Daten werden mit anderen verknüpft, zu Personenprofilen und als Netzwerke dargestellt aufgrund von Fragen wie: Wer wohnt in der Nähe? Wer war auf derselben Veranstaltung? Eine Klage beim BVerfG ist anhängig.
Wird gegen geltende rechtliche Bestimmungen verstoßen, können empfindliche Strafen verhängt werden und wurden in der Vergangenheit verhängt. Somit geschieht das Sammeln von Daten nicht im rechtsfreien Raum, vielmehr gibt es eine Reihe von Grundsätzen zu beachten. Ausdrücklich hingewiesen sei beispielsweise auf die Datenschutz-Grundverordnung (DSGVO).
Nachfolgend die wichtigsten Prinzipien:

Generell empfiehlt es sich, eine Datenschutz-Folgenabschätzung durchzuführen, um mögliche Risiken für die Privatsphäre Betroffener zu identifizieren und zu bewerten.
Datenschutz auf EU-Ebene
Auch die Europäische Union hat auf die Herausforderungen resultierend aus dem Einsatz von KI reagiert und mit dem “EU-Gesetz zur künstlichen Intelligenz” einen legislativen Rahmen geschaffen, der zumindest in der EU verbindlich ist. Im Artikel 5 heißt es sinngemäß:
KI-Systeme stellen ein unannehmbares Risiko dar, wenn sie als Bedrohung für Menschen gelten; diese KI-Systeme werden verboten. Sie umfassen:
kognitive Verhaltensmanipulation von Personen oder bestimmten gefährdeten Gruppen, zum Beispiel sprachgesteuertes Spielzeug, das gefährliches Verhalten bei Kindern fördert;
Soziales Scoring: Klassifizierung von Menschen auf der Grundlage von Verhalten, sozioökonomischem Status und persönlichen Merkmalen;
biometrische Identifizierung und Kategorisierung natürlicher Personen;
biometrischen Echtzeit-Fernidentifizierungssystemen, zum Beispiel Gesichtserkennung.
Schneller als man denkt, ist man im Wirkungskreis dieses Gesetzes. So können bspw. Prognosemodelle zur Gruppenzugehörigkeit von Kunden in Top-Buyer, Low-Buyer und Average-Buyer bereits unter das EU-KI-Gesetz fallen, insbesondere wenn sie in einer Weise verwendet werden, die individuelle Entscheidungen beeinflusst oder erhebliche Auswirkungen auf Kunden hat. Das EU-Gesetz benennt folgende Risiko-Kategorisierungen:
Minimales/kein Risiko (z. B. reine Empfehlungssysteme für Inhalte)
Begrenztes Risiko (z. B. Chatbots, die explizit als KI gekennzeichnet sind)
Hohes Risiko (z. B. KI-Systeme, die wirtschaftliche Chancen, Kredite oder personalisierte Preise beeinflussen)
Unannehmbares Risiko (z. B. Social Scoring oder manipulative KI)
Somit fällt ein solches Modell möglicherweise in die Kategorie "hohes Risiko", insbesondere, wenn es:
Einfluss auf individualisierte Angebote oder Rabatte hat
Die Entscheidung über den Zugang zu bestimmten Dienstleistungen oder Kreditvergaben beeinflusst
Zu potenzieller Diskriminierung führt, indem es Gruppen benachteiligt (z. B. wenn bestimmte Kundengruppen systematisch schlechtere Angebote bekommen)
Wenn das Modell lediglich zur internen Analyse genutzt wird, um Marketingstrategien zu planen, könnte es unter ein begrenztes Risiko fallen. Sobald aber automatisierte individuelle Entscheidungen getroffen werden, die Auswirkungen auf den Kunden haben (z. B. dynamische Preisgestaltung, exklusive Angebote), könnte es als hochriskante KI gelten.
Falls das Modell als hochriskantes KI-System eingestuft wird, müssen folgende Vorgaben erfüllt werden:
Dokumentation und Transparenz: Nachvollziehbare Entscheidungsgrundlagen müssen dokumentiert werden.
Bias-Vermeidung: Sicherstellen, dass das Modell nicht bestimmte Gruppen benachteiligt.
Menschliche Aufsicht: Automatisierte Entscheidungen sollten überprüft und beeinflussbar sein.
Datenqualität: Die Trainingsdaten müssen repräsentativ und diskriminierungsfrei sein.
Fazit: Wenn ein Modell nur zur internen Analyse genutzt wird, besteht eher ein begrenztes Risiko. Sobald es individuelle Entscheidungen beeinflusst, z. B. durch gezielte Marketingmaßnahmen oder Preisgestaltungen, sollte man es als potenziell hochriskantes KI-System behandeln und entsprechende Maßnahmen zur Compliance ergreifen.

Es scheint vor diesem Hintergrund anzuraten, hier Vorsicht walten zu lassen. Hierbei ist nicht ausschließlich davon auszugehen, dass nur direkt Betroffene zu Klägern werden; auch der Mitbewerb könnte ein Interesse daran haben, Ihren Wettbewerbsvorteil durch sinnfreie Beschäftigung Ihres Unternehmens mit rechtlichen Aspekten zu überkompensieren. Last but not least: Die Strafen sind empfindlich.
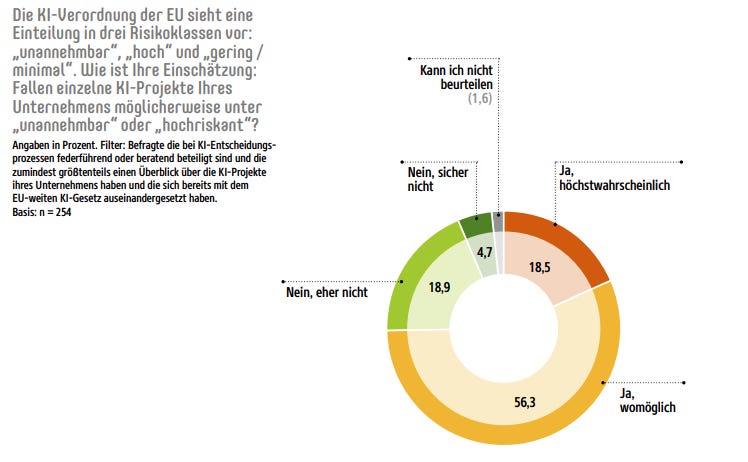
Das diese Einschätzung nicht aus der Luft gegriffen ist, zeigt die Studie “AI-ready Enterprise 2024” Innerhalb derer 56% der Befragten die Einschätzung haben, dass einige ihrer KI-Projekte in die obersten Klassen „unannehmbar“ und „hochriskant“ fallen.
Hier geht es zum Folgeartikel, hier geht es zum vorherigen Post. Bleiben Sie mir gewogen.
