

EventBus und Microservices - a Case Study: Part I
Was so alles schiefgehen kann und welche Konsequenzen das haben kann. Oder wie ein zunächst kleines Problem ...

Die Artikel dieser Reihe
Einleitung
This is a true story!

Dieser Artikel (nebst den folgenden Artikeln) beschreibt die Erfahrungen, die in einem konkreten Projekt gemacht wurden. Diese Serie beschreibt, wie ein paar kleine Fehler am Anfang gravierende Konsequenzen haben können; sie soll (im besten Fall) Hinweise geben, diese zu vermeiden. Alles Beschriebene ist keine Raketenwissenschaft und für viele meiner geschätzten Kollegen Teil der täglichen Arbeit … aber es gibt auch die Anderen.
Die Artikelserie verzichtet bewusst auf Implementierungsdetails (wo möglich), es ist vollkommen gleichgültig, welcher Technologiestack verwendet wird. Dennoch werden - zumeist zur Illustration - konkrete Technologien benannt, verwendet, was auch immer.
Im Vordergrund dieser Artikelserie steht die Entwicklung eines Ansatzes mit einer gewissen Allgemeingültigkeit und der Weg dahin.
What is it about?
Microservices sind eines der dominierenden Themen in der modernen Software-Entwicklung. Moderne Frameworks wie Quarkus oder Spring Boot erlauben eine schnelle und kostengünstige Entwicklung der Geschäftsfunktionalität; Docker, Kubernetes usw. unterstützen den Betrieb dieser Lösungen in puncto Skalierbarkeit und Ausfallsicherheit.
Doch darum soll es hier gar nicht im Detail gehen, die Technologien sind vorhanden und ausgereift doch im Projektalltag tauchen oftmals Probleme an Stellen auf, an denen man sie so vielleicht leicht übersehen kann; die Folgen sind unter Umständen gravierend.
Die Ausgangssituation
Das mich beauftragende Unternehmen erbringt eine ganze Reihe von B2B-Dienstleistungen, alle diese Dienstleistungen sind in individuellen Applikationen über einen längeren Zeitraum entstanden und wie üblich mehrten sich die Probleme im Zeitablauf. Die größten Probleme wurden mir wie folgt geschildert:
Wir haben große Probleme in der Kommunikation der Applikationen, das funktioniert nie richtig und der Betrieb verbringt signifikante Zeit damit, auftretende Inkonsistenzen in den unterschiedlichen Daten der Applikationen manuell zu beheben.
Wir haben verschiedenste Formen der Schnittstellen. Daten werden von Drittanbietern teilweise über Dateischnittstellen übernommen. Für die interne Kommunikation nutzen wir häufig JMS und/oder REST.
Was benutzt wird hängt mit unserem Zonenmodell und den hohen Sicherheitsanforderungen zusammen, REST bspw. vertrauen wir nicht. Bei JMS hängen wir auf einer alten JMS 1.0 - konformen Lösung fest, hier trauen wir uns nicht an ein Update heran.
Weiterhin haben wir eine Flut von JMS Queues / - Topics, kaum einer weiß, wozu einzelnen Queues und / oder Topics verwendet werden, einfach abschalten hat oftmals zu Chaos geführt.Wir haben ein zyklisches Lastverhalten, geprägt durch Peaks am Ende des Monats und/oder des Quartals, daher setzen wir stark auf asynchrone Kommunikation.
Unser größtes Problem haben wir aktuell in der Anbindung der einzelnen Produktionssysteme (also die fachlichen Systeme mit direkter Kundeninteraktion) und dem Abrechnungssystem. Hier kam es in der Vergangenheit zu nicht gestellten oder mehrfach gestellten Rechnungen / Rechnungspositionen. Das hat einen erheblichen Reputationsschaden zur Folge gehabt und den Vorstand nervlich Jahre seiner Lebenszeit gekostet.
Was nicht so explizit addressiert wurde, aber innerhalb allerkürzester Zeit klar wurde: die interne Organisation und das Konglomerat aus Applikationen uns Services war ein mustergültiges Beispiel für Conway’s Gesetz mit allen resultierenden (negativen) Konsequenzen.
“Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.”
— Mel Conway
Die (meine Aufgabe) - ganz banal:
Wir brauchen ein allgemeines Konzept für die Kommunikation von Services welches die genannten Probleme allgemeingültig addressiert, am dringlichsten ist das Problem der Rechnungsstellung.
Das dringlichste Problem
Umreissen wir das dringlichste Problem:
Der Kunde erbringt eine materielle Dienstleistung - gleichgültig welche Dienstleistung und welcher Kunde - und diese Dienstleistung beinhaltet die Produktion eines gewissen Gutes - des Produkts - und dessen Versand sowie die zugehörige Rechnungsstellung. Vermutlich ist dieses Modell ist hinreichend allgemein und dürfte so ziemlich auf jedes Unternehmen zutreffen. Weiterhin ist es so stark simplifiziert, dass auf den ersten Blick eigentlich die Lösung kaum Probleme erwarten lässt.
Ursprünglich war das System monolithisch aufgebaut, die Wartungskosten und die Kosten der Weiterentwicklung wuchsen (und wuchsen und wuchsen), allen Beteiligten war klar: So geht es nicht weiter. Microservices, der weiße Ritter!

Eigentlich machte man alles irgendwie richtig, man schnitt das Gesamtsystem in Bounded Contexts, irgendwie war den Implementierungen auch etwas wie eine hexagonale Architektur anzumerken. Man implementierte die Einzelkomponenten als Services, implementierte eine eigene Datenhaltung für jeden Service, versah sie mit JMS und REST-Interfaces und schon läuft alles wie gewünscht. So hatte man sich das gedacht.
Nehmen wir also an, dass das Systems stark vereinfacht in etwa so aussehen hat:
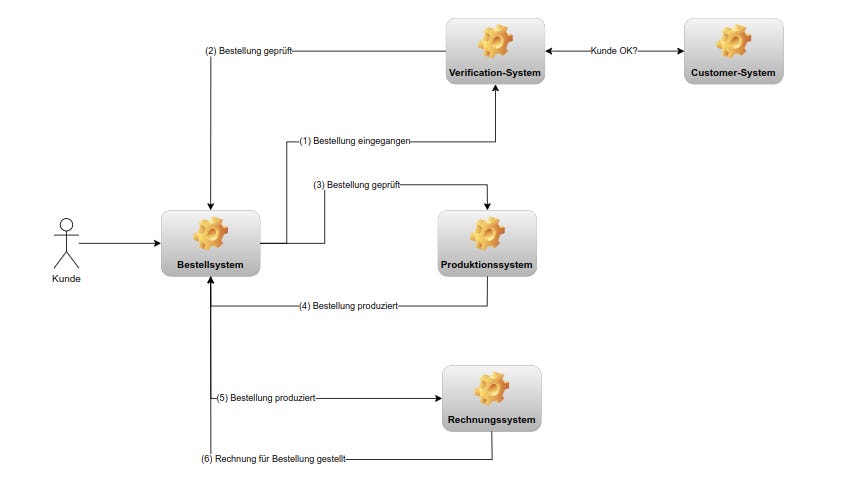
Alles erschien richtig gemacht, doch dann: viel Geld investiert und dann ein Tal der Tränen und der Ernüchterung.
Where is the beef?
… fragt man sich, wenn man die obige Grafik so sieht.
Folgendes trat bei dem Kunden auf:
Das Produktionssystem tat alles das, was es tun sollte, fehlerfrei.
Das Produktionssystem speicherte den aktuellen Status des Produktionauftrages.
Das Produktionssystem meldete den Auftrag als “korrekt abgearbeitet“ an das Rechnungssystem (und an das Bestellsystem, das Customer Care System, das Business Activity Monitoring usw.)
Es traten Inkonsistenzen zwischen dem Produktionssystem (inklusive dem Versand des erstellten Guts) und dem Rechnungssystem auf; ein Fiasko nahm seinen Lauf.
Es ist jedem unmittelbar einleuchtend, dass ein abgeschlossener Produktionsauftrag respektives eines zum Kunden verschicktes Produkt einfach mit der zugehörigen Rechnungsstellung passen müssen; war aber nicht so.
Man braucht nicht viel Phantasie um sich vorstellen zu können, dass diese Problem mittels kürzester Zeit die Aufmerksamkeit des Vorstands erregte und tagelang kein anderes Thema dominierte.
Doch was war passiert?
Werfen wir einen Blick auf die konkrete Implementierung wie sie vorgefunden wurde:

Auf welche Art auch immer (hier unerheblich) wurde der Produktionsauftrag von einem Client als angeschlossen gemeldet. Der entsprechende Service-Endpoint verarbeitete diese Nachricht indem der Auftrag (hier: ProductionOrder) gespeichert wurde und ein MessageLog Eintrag geschrieben wurde.
Was trat nun auf?

In sehr seltenen Fällen schlug der Insert des Message Logs fehl, als Konsequenz war dort nichts vorhanden, was der MessageOutAdapter versenden konnte.
Konsequenz: keine RechnungsstellungDurchaus häufiger trat das Phänomen auf, dass der Insert des MessageOutAdapters in das MessageLog fehlschlug und Nachrichten in Konsequenz wiederholt versendet wurden.
Konsequenz: n-fache Rechnungsstellung
Die Transactional Outbox
Noch vor meiner Zeit hatte man sich das transaktionale Verhalten beider Inserts gespart, das Ergebnis war (teilweise) höchste Kundenzufriedenheit. Man erhielt ein Produkt doch nie eine Rechnung. Man hat zwar den Zustand des Produkts entsprechend geändert aber der fehlgeschlagene Insert in das Event-Log verhinderte zuverlässig die Benachrichtigung des Abrechnungssystems. Anders herum traten (weniger) Fälle auf, in denen man eine Rechnung versendete (Insert in Event-Log erfolgreich, in der Produktion - nebst Versand - jedoch nicht).

Die Lösung ist zugegeben einfach und einschlägig als Transactional Outbox bekannt; obige Grafik gibt die Implementierung der Transactional Outbox bereits wieder.
Beide Inserts liefen innerhalb einer lokalen Transaktion, das funktionierte auch wunderbar; Inkonsistenzen innerhalb des einen Systems traten nicht auf. Die Einträge in das Eventlog (welches keines ist/war, später dazu mehr) wurden zyklisch ausgelesen und asynchron per JMS (auch hierzu später mehr) versendet. Natürlich musste in einem letzten Schritt der erfolgreiche Versand vermerkt werden. Und genau da lag ein weiteres Problem und das Problem hat einen Namen.
Das Dual Write Problem
Generell gesprochen tritt dieses Problem immer dann auf, wenn Daten in unterschiedlichen Systemen aktualisiert werden sollen und dem transaktionalen Verhalten der Systeme / der Nachrichtenübermittlung nicht genügend Beachtung geschenkt wird.
Was war also geschehen?
Entwickler (und Architekten, ich nehme meinen Berufsstand nicht heraus) tendieren dazu die Dinge zu simplifizieren. Eigentlich ist ja das (Abstraktion und Simplifizierung) ein wesentliches Merkmal unserer Tätigkeit: KISS (Keep it simple, stupid).
Unterstellen wir für den Moment, dass die Benachrichtigung des Abrechnungssystems mittels REST erfolgte (tatsächlich war es JMS, das war aber nicht wirklich von Belang für das Problem).
Also ließt der OutboundAdapter das EventLog (welches ja eigenlich keines war) zyklisch aus, erstellt die Nachricht und versendet diese. Geht hier irgendetwas schief ist das noch kein Problem. Problematisch wird das Ganze nur, wenn der nachfolgende Update des EventLogs fehlschlägt.
Dieses hatte zur Konsequenz, dass beim nächsten Lesezyklus die entsprechende Nachricht einfach nochmal versendet wurde. Nachdem man also:
entweder keine Rechnung versendet hatte (Lösung: Transactional Outbox)
versendete man jetzt einfach 1 -n Rechnungen (keine transaktionale Absicherung des Sendens (REST) und des Schreibens (INSERT/UPDATE EventLog)

Der unmittelbare Gedanke war: weitere Transaktion. Doch das Ganze sollte sich als weitaus komplizierter herausstellen.
Wie konnte es soweit kommen?
Eigentlich kein Wunder, man begegnet dem Leben doch mit einer eher optimistischen Haltung und der Glaube an die eigenen Lösungen ist (lange Zeit) ungebrochen. Wären da nicht die Fallacies of Distributed Systems:

Jeder der obigen Annahmen1 ist falsch, was schiefgehen kann wird schiefgehen - be prepared!
Also, was tun? Im Grunde bieten sich zwei Lösungen an:
transaktionale Absicherung des Sendens und der Änderung des Event-Logs
Ignorieren der doppelten Nachricht auf der Empfängerseite
Aber ich will nicht vorgreifen, das Lösungsspektrum wurde kundenseitig viel weiter gefasst, die Highlights der Diskussion:
Microservices (mit eigener Datenhaltung) sind untauglich.
Messaging ist untauglich, die Alternativen sind samt und sonders unsicher/inperformant/sonstiges Teufelswerk
Hätten wir gleich auf xyz (proprietär) gesetzt, dann wäre uns das nicht passiert.
…
Jetzt kann man als externer Consultant diese Einwände ja nicht abtun. Richtig spannend wurde das Ganze, als unvermutet weitere Bereiche des Unternehmens sich meldeten und Dinge berichteten wie:
Bei uns klappt die Integration des binären, externen Document-Stores und die (interne) Verknüpfung der Dokumente nicht.
Wir haben eine file-basierte Schnittstelle zu System X, das funktioniert nie richtig. Wir meinen die Daten sind übertragen und vermerken das, in Wirklichkeit hat das nicht funktioniert.
Wie es weiterging und wie wir uns im Projekt aus dem konkreten Problem einem Lösungsdesign angenähert haben dann in folgenden Artikeln; hier geht es zum zweiten Teil.
Bleiben Sie mir gewogen.
Grafik entnommen: https://architecturenotes.co/fallacies-of-distributed-systems/