

KI: More human than human? (Teil I)
Perhaps we should all stop for a moment and focus not only on making our AI better and more successful but also on the benefit of humanity. — Stephen Hawking 2017

Einleitung

Motivation
Ich habe in dieser Artikelserie ausschließlich KI-generierte Bilder verwendet und war doch erstaunt, zu was KI heute schon in der Lage ist. Aus meinem persönlichen Umfeld (meine Stieftochter studiert Kunst & Design) motiviert, kamen mir Zweifel, ob das, was hier entwickelt wurde nicht eventuell etwas vorschnell als grandioser Fortschritt der Menschheit anzusehen ist. Wie komme ich auf solche Gedanken?
Als ich die Artikelserie u.a. auf linkedin veröffentlichte, wurde mir freundlicherweise folgendes Angebot unterbreitet:

Na besten Dank, nicht nur die Bilder “synthetisch” sondern auch mein Text KI-optimiert? Da will etwas anonymes mich (!!!) optimieren? Es war ja schon starker Tobak, dass die Bilder hinsichtlich Kreativität und Qualität vergleichbar zu den Arbeiten meiner Stieftochter sind und nun auch noch das.
Ich habe es nicht ausprobiert … hätte ich es sollen? Wahrscheinlich schon.
Analytische- und Generative KI
Unbewusst mischen sich die Dinge. Ging es bei dem simplen Beispiel der Vorhersage der Lieferzeitpunkte in den ersten Artikeln um die Analyse und Interpretation von Daten, geht es in der Einleitung dieses Artikels darum, dass neue Inhalte erzeugt werden die den Mustern der Eingabedaten entsprechen Beides sind sind komplementäre Technologien mit unterschiedlichen Schwerpunkten. Die zugrunde liegenden Algorithmen sind oftmals gleich.
Ich habe mir das Vergnügen gemacht, ChatGPT mit folgender Aufgabe zu konfrontieren:
Erstelle einen cloud-nativen Service in Java mittels microprofile.io für die Vorhersage von Produktionsdauern in Abhängigkeit von geplanter Menge und in Produktion befindlicher Menge auf Basis einer linearen Regression. Alle Konfigurationsdateien wie maven.pom, Dockerfile sind ebenfalls zu erstellen. Die Anfragen und die Ergebnisse sollen in einer relationalen Datenbank gespeichert werden. Dabei soll eine hexagonale Architektur genutzt werden. Hierbei sind geeignete Testklassen ebenfalls zu implementieren. Ein Linux Shell Skript für die Projektstruktur ist ebenfalls zu generieren
Lassen Sie sich mal von dem Ergebnis überraschen … ich würde es mal so ausdrücken: es ging ein klitzekleines bißchen schneller. Lassen Sie sich das mal auf der Zunge zergehen: Die Nutzung einer GenAI-Lösung ermöglicht die Erstellung einer Lösung für analytische KI.
Aber: Die Beurteilung der Güte des Ergebnisses - selbst wenn man sich die Tests generieren lässt - dazu braucht es immer noch jemanden, der etwas von der Materie versteht.
Hilflose wiederholte Generierungsversuche mittels Variation des Eingabetextes um ein wunschgemäßes Ergebnis zu erhalten - viel Spaß damit. Auch wenn es bereits Dekaden her ist, ich erinnere mich nur zu genau an das Scheitern einer Model-driven Architecture und die Gründe hierfür.
Wie lässt sich das alles erklären?
Tradeoff zwischen Erklärbarkeit und Genauigkeit
Sie erinnern sich an den Machine Learning Modeling Cycle?
 Modeling Cycle")
Einer der Punkte im Schritt “Train Models“ war der Punkt “Select Algorithms”. Als Heuristik gilt, je komplexer und weniger nachvollziehbar der Algorithmus, desto besser die Prognosegenauigkeit:

Kurz und bündig, Lineare Regression (siehe die anderen Artikel) ist leicht nachzuvollziehen, beim Deep Learning mittels Neuronaler Netze sieht das schon ganz anders aus.
Trust me, I’m infallible
… schön wäre es.
Wenn irgend jemand in der Vergangenheit kraft seines Wissens und Kraft seiner Imagination und Kreativität erschaffen hat, dann bin ich mir sehr sicher, dass das Ziel dessen zumindest vor dem geistigen Auge klar definiert war sowie der Weg zum erwünschten Ergebnis geplant und nachvollziehbar war.
Mit KI ist das teilweise anders. Hier ist das Ziel definiert, der Weg dahin bleibt für die mit der Erstellung des KI-Systems betrauten oftmals nicht nachvollziehbar. Aber vielleicht ist es ja ganz sinnvoll, das Ganze wenigstens in Ansätzen zu versuchen zu verstehen - so ging es mir jedenfalls.
Werfen wir also einen Blick darauf, wie neuronale Netze funktionieren.
More human than human is our Motto
… das hatten wir schon, Dr. Eldon Tyrell

Neuronale Netzwerke1 sind hinsichtlich Struktur und Funktion ähnlich dem menschlichen Gehirn aufgebaut. Es gibt jedoch einen fundamentalen Unterschied: das menschliche Gehirn lernt permanent, ein neuronales Netzwerk normalerweise nur während der Trainingsphase.
Ganz grob ausgedrückt: Das (menschliche) Gehirn ist aus Neuronen und Synapsen aufgebaut; jedes Neuron empfängt Signale, verarbeitet sie und gibt eine Ausgabe weiter - über Synapsen an weitere Neuronen.
Ob ein Neuron “feuert” oder nicht, hängt von Schwellenwerten ab; bei künstlichen Neuronen ist das die sogenannte Aktivierungsfunktion; Sigmoid- oder ReLU in den meisten Fällen.
Im einfachsten Fall (nur ein Neuron = Perceptron) sieht das Ganze dann so aus:

Die Funktionsweise ist wie folgt:
Die Eingangswerte Input1 und Input2 werden mit den zunächst wilkürlich gewählten Gewichten multipliziert und addiert, ein sogenannter Bias (zusätzliche Dimension zur Anpassung an die Trainingsdaten) hinzugefügt und dann wird der Output über die Aktivierungsfunktion berechnet. Diesen Schritt bezeichnet man als Vorwärtspropagation.
Das Lernen des Perzeptrons geschieht - vereinfacht ausgedrückt - darin, dass die Gewichte mittels eines Optimierungsalgorithmus (Gradientenabstieg) über die Lernzyklen (die sog. Epochen) so angepasst werden, dass der Output dem erwarteten Wert entspricht. Diesen Schritt bezeichnet man als Rückwärtspropagation. Also: viel lernen führt zu guten Ergebnissen.
Vom Verständnis eines Perzeptrons zum Deep Learning ist es nun nur noch ein kleiner Schritt; ganz grob gesagt: Neuronen in Schichten (plus ein paar andere Zutaten).

Ein Beispiel:
Ein neuronales Netzwerk soll die Märchen der Gebrüder Grimm dahingehend durchgehen, dass ermittelt wird, ob es sich um das Märchen Rotkäppchen handelt. Jetzt kann man natürlich alle Texte dahingehend scannen, ob der String “Rotkäppchen“ darin vorkommt und wie oft er darin vorkommt. Doch so einfach wollen wir es uns nicht machen; wenn Shrek, Schneewittchen und das Rotkäppchen Konversation am Lagerfeuer betreiben, dann kommt im Transkript des Gesprächs sicherlich oft “Rotkäppchen“ vor; ob es sich dabei um das Märchen der Gebrüder Grimm handelt ist jedoch fraglich.

Also definieren wir, dass ein Märchen (Text) in dem ein Wald, ein Korb, ein Wolf und eine Großmutter ziemlich sicher das Märchen vom Rotkäppchen sein wird.
Das Ganze bspw. in Python formuliert:
# Trainingsdaten: [Wald, Großmutter, Wolf, Korb]
inputs = np.array([
[1, 1, 1, 1], # Rotkäppchen
[1, 1, 1, 0], # Geschichte ohne Korb
[1, 1, 0, 1], # Geschichte ohne Wolf
[1, 0, 1, 1], # Geschichte ohne Großmutter
[0, 1, 1, 1], # Geschichte ohne Wald
[0, 0, 0, 0], # Keine Elemente von Rotkäppchen
])
# Zielwerte: 1 für Rotkäppchen, 0 für nicht Rotkäppchen
targets = np.array([[1], [0], [0], [0], [1], [0]])Trainiert und testet man das Neuronale Netzwerk mit Geschichten wie:
new_stories = np.array([
[1, 1, 1, 1], # Rotkäppchen
[0, 0, 1, 0], # Geschichte mit einem Wolf
[0, 1, 1, 1], # Geschichte ohne Wald
[1, 1, 0, 1], # Geschichte ohne Wolf
[1, 0, 1, 1], # Geschichte ohne Großmutter
])Dann sollte man erwarten können:
Geschichte: [1 1 1 1] -> Rotkäppchen: True
Geschichte: [0 0 1 0] -> Rotkäppchen: False
Geschichte: [0 1 1 1] -> Rotkäppchen: True
Geschichte: [1 1 0 1] -> Rotkäppchen: False
Geschichte: [1 0 1 1] -> Rotkäppchen: FalseDas soll zunächst für das Verständnis reichen, stellen Sie sich doch einmal die Frage nach der Erklärung des Ergebnisses und dem Debuggen bei 1000 Trainingszyklen mit Vorwärts- und Rückwärtspropagation.
Und nun noch ein paar Hard-Facts zu GPT-4: Die 175 Milliarden Parameter (= Input-Neuronen) in der Version GPT-3, wurden mit einer unglaublich großen Menge an Textdaten trainiert (das englische Wikipedia macht nur 0,6 % davon aus). Wie ChatGPT funktioniert ist in diesem Artikel gut erklärt.
Blindflug ohne Explainable AI
Wussten Sie, das KI halluzinieren kann? Lesen Sie doch mal diesen Artikel.

Mittlerweile gibt es so einige Beispiel für irre Ergebnisse bei der Nutzung von Deep Neuronal Networks …
Wenn Bananen Toaster sind oder Huskys zu Wölfen mutieren

Ein paar prominente Real-World Beispiele für das, was passieren kann, wenn man eine Neuronales Netzwerk falsch anlernt sind:
Probleme bei der Klassifikation von Huskies und Wölfen
Probleme beim Erkennen von Bananen auf Bildern
Unfug als Antwort von ChatBots
…
Obige Beispiele hängen insbesondere damit zusammen, dass man entweder das Neuronale Netz mit fragwürdigen Daten angelernt hat und dieses teilweise sogar mit Absicht gemacht hat und/oder das Neuronale Netz schlicht auf falsche Features hin optimiert hat. Im Falle der Huskies bspw. hatte man ein Neuronales Netz unbewusst so trainiert, dass es ganz wunderbar Schnee auf Bildern klassifizieren konnte. Die Tiere waren dem Neuronalen Netz schlussendlich egal …

“Erkrankungen“ einer KI
… glauben Sie nicht, gibt es aber!

Stellen wir uns einfach vor, das eine GenAI bspw. Bilder auf der Basis von irgendwie und irgendwo als Trainingsdaten aufgesammelten Bildern generiert; das haben wir in dem Artikel ja nun zur Genüge gesehen. Was passiert nun, wenn man die KI-generierten Bilder wiederum als Trainingsdaten verwendet usw. (self-consuming loop).
Eine neue Studie von Forschern der Rice University und der Stanford University in den USA zeigt, dass die Qualität von KI-Systemen leidet, wenn sie mit synthetischen, maschinell erstellten Eingaben trainiert werden und nicht mit Texten und Bildern, die von echten Menschen stammen. Die Forscher bezeichnen diesen Effekt als Model Autophagy Disorder (MAD). Die künstliche Intelligenz frisst sich quasi selbst auf, was bedeutet, dass es Parallelen zum Rinderwahnsinn gibt - einer neurologischen Störung bei Kühen, die mit den infizierten Überresten anderer Rinder gefüttert werden.
Die Studie zeigt, dass ohne frische Daten aus der realen Welt die Qualität oder die Vielfalt der von der künstlichen Intelligenz produzierten Inhalte abnimmt - oder beides. Und da bereits ein gehöriger Anteil der Daten im Internet KI-generiert ist, ist das doch eine interessante Perspektive.
Social Media: Laut einer Studie von 2020 werden schätzungsweise 30-50% der Inhalte in sozialen Medien durch Bots oder automatisierte Systeme erzeugt oder verbreitet.
Suchmaschinen: Analysen zeigen, dass der Anteil der KI-generierten Inhalte, die in den bestbewerteten Ergebnissen von Google erscheinen, bereits ca 14% ausmachen
Journalismus: Einige große Nachrichtenagenturen nutzen KI zur Erstellung von Artikeln. Associated Press bspw. hat seit 2015 eine KI eingesetzt, um Quartalsberichte von Unternehmen zu schreiben. Machen Sie sich doch mal die Mühe ChatGPT mit folgendem zu beauftragen: “Schreibe einen kritischen Bericht über die ki-gestützte Überwachung der Olympischen Spiele in Paris mit Bezug zum EU AI Act“. Ein wenig redigieren und schon …
Vertrauen als Maßstab
Vertrauen ist alles, nehmen wir ein Beispiel (in Anlehnung an ein Paper des Software Engineering Institute der Carnegie Mellon University, 2022)
Eine Produktionslinie innerhalb derer potentiell gefährliche Verrichtungen durch die Operateure der Produktionsanlage verrichtet werden. Die Einführung von KI und Machine Learning soll diesen Operateuren helfen, sichere Entscheidungen zu treffen; verbunden mit der Hoffnung, dass dieses Modell ihr Geschäft revolutionieren wird, indem es die Effizienz und Sicherheit der Arbeiter verbessert. Nach der Einführung stellt man fest, dass das System durch die Benutzer kaum angenommen wird. Der Grund für die fehlende Akzeptanz ist, dass das Vertrauen in das System seitens der Anwender nicht existiert. Die Nutzer insistieren die Entscheidungsprozesse zu verstehen, die den Systemen zugrunde liegen, mit denen sie arbeiten sollen - insbesondere in Situationen, in denen es um viel geht.
Die folgende Grafik der DARPA bringt es auf den Punkt:

Doch wie sieht es mit der Erklärbarkeit aus (siehe oben … Tradeoff …)?
Transparenz auf dem Weg zum Ergebnis
Without completely new explanatory mechanisms, the output of today’s Deep Neural Networks (DNNs) cannot be explained, neither by the neural network itself, nor by an external explanatory component, and not even by the developer of the system.
— Feiyu Xu et al.
Ist das nicht ein beruhigender Gedanke: das, was Deep Neuronal Networks als Ergebnis ausgeben kann nicht erklärt werden:
nicht durch das neuronale Netzwerk,
nicht durch externe Komponenten,
nicht durch die Entwickler des Systems.
Die folgende Grafik - ebenfalls herausgegeben von der DARPA - verdeutlicht die Zusammenhänge:
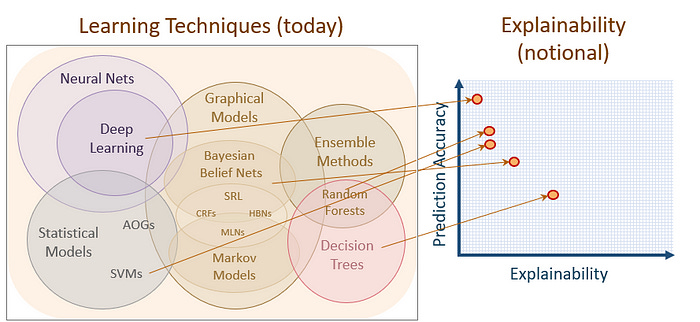
Die meisten verwendeten Machine- und Deep-Learning-Verfahren sind sog. Black Box Modelle, innerhalb derer im Nebel bleibt, was genau in ihnen passiert.

Sie haben das “Tomorrow“ zur Kenntnis genommen? Also “Today“ ist das nicht so.
Die Nachvollziehbarkeit gliedert sich hierbei in verschiedene Bereiche:
die Erklärung des Modells als solchem
die Erklärung des Ergebnisses, bspw. durch Variation der Eingangsvariablen.
Auch wenn die Erklärung des Modells in Teilen plausibel erscheint - bspw. indem man aus einer Unmenge von Texten die Regeln synthetisiert die mit bestimmten Wahrscheinlichkeiten Antworten abbilden, wird es bei der Variation von Eingangsvariablen und der Erklärung des resultierenden Ergebnisses manchmal doch recht schwer. Ziehen Sie bitte nicht das simple Beispiel einer Regressionsanalyse heran, wir reden hier von einem ganz anderen Kaliber. Das GPT-3 Modell hat rund 175 Milliarden Parameter …
Zusammenfassung
Die Ergebnisse insbesondere von GenAI ist beeindruckend, keine Frage, aber besser ginge es wohl allen, wenn man den Weg zum Ergebnis nachvollziehen könnte und nicht einem Ding gegenübersteht, welches zwar das tut, was es soll, aber niemand weiß so genau, warum. Und bei einigermßen klarem Blick sollte man auch sehen, dass KI das Potential hat, in das Leben von fast jedem einzugreifen oder es bereits tut.
Wir brauchen also Ansätze um zu verstehen, was das, welches “wir” schufen eigentlich gerade so treibt. Na denn, warum nicht ein wenig Vertrauen investieren und optimistisch sein, es geht ja um fast nichts, außer ….