

Silizium-Intuition: Machine Learning (Einleitung)
Oh mein Gott: Nicht schon wieder etwas zu diesem Thema!

Über diese Artikelserie
„Denn die richtige Berechnung ist das Kriterium der Wahrheit.“
-- Epikur im Brief an Herodot

Nachfolgend - und in lockerer, unregelmäßiger Folge - verschiedene Aspekte im Kontext des Machine Learning. Teilweise ein deep-dive, teilweise vielleicht zu oberflächlich; aber hoffentlich immer interessant.
Zu Beginn wird ziemlich viel nicht-technisches kommen, das ändert sich - versprochen. Wollen Sie Technik, dann bitte Geduld.
Die eher nicht-technischen Aspekte werden im Teil 1 behandelt (welcher aus verschiedenen, nummerierten Posts besteht):wirtschaftliche Bedeutung, Agilität und Projektmanagement.
Teil 2 beschäftigt sich dann mit der Data Preparation, einem der aufwändigsten Teile bei ML Projekten).
Nachfolgend wird es um den Aufbau von Data Preparation Pipelines gehen bevor Modelle für Regression, Klassifikation und Clustering angegangen werden - aber: alles locker und unregelmäßig.
Inhalt dieses Artikels
Disclaimer:
Bleiben Sie kritisch! Hier die Links zu älteren Artikeln mit einer durchaus kritischen Betrachtungsweise der Thematik KI:
Einleitung (der Einleitung)
Epikur (341–270 v. Chr.) war ein Materialist, der die Welt naturalistisch erklärte. Sein Wahrheitskriterium lautete:
Sinneswahrnehmungen sind grundsätzlich verlässlich.
Fehler entstehen durch falsche Interpretationen (z. B. voreilige Schlüsse).
„Richtige Berechnung“ korrigiert diese Fehler – durch logische Analyse, Abwägen von Hypothesen und empirische Überprüfung.
Wie würde Epikur Machine Learning und Künstliche Intelligenz bewerten?

Wenn es ein dominierendes Thema in der IT des Jahres 2024 gegeben hat, dann war es das Thema “Künstliche Intelligenz”, speziell das Thema Generative KI. Besonders amüsiert habe ich mich über die Data Science Conference Bingo Card von Big Data Borat:

Wenn es das Thema GenAI in aller Munde geschafft hat, ist dann eine Ausarbeitung zu Machine Learning nicht etwas aus der Zeit gefallen, gibt es noch nicht genug zu dem Thema? Die Antwort hängt vom Leser ab, doch was sind die Motive hinter dieser Ausarbeitung?
Machine Learning - die nicht so offensichtliche KI
Es liegt hauptsächlich an der Wahrnehmung und der Zugänglichkeit von KI-Technologien: GPT-Modelle und andere generative KI-Anwendungen sind für Unternehmen und Endnutzer besonders sichtbar, da sie direkt über Chatbots, Textgeneratoren oder Code-Vervollständigung genutzt werden können. OpenAI, Google, Meta usw. erfahren massive Publicity.
Machine Learning (ML) im klassischen Sinne, also Predictive Analytics, Clustering oder Optimierung, arbeitet oft "hinter den Kulissen" und ist weniger spektakulär in der Außendarstellung. Dennoch ist Machine Learning quasi allgegenwärtig – von der Art, wie wir online shoppen, bis hin zu medizinischen Diagnosen und autonomen Fahrzeugen. Die Technologie wird immer unsichtbarer, aber ihre Auswirkungen sind enorm.
GenAI ist einfacher zugänglich; Unternehmen können GPT-Modelle ohne tiefgehendes ML-Know-how nutzen, während klassische ML-Projekte oft spezialisierte Data Scientists erfordern. GenAI liefert quasi sofort Ergebnisse für Text, Bilder oder Code. Predictive ML-Lösungen brauchen mehr Datenaufbereitung, Trainingsphasen und eine Anbindung an bestehende Geschäftsprozesse. Klassische ML-Anwendungen in Logistik, Betrugserkennung oder Kundensegmentierung laufen eher im Hintergrund und schaffen nicht so viele Schlagzeilen und teilweise fehlt das Bewusstsein für die Wertschöpfung durch ML – welches oft einen viel direkteren ROI bringt als ein KI-gestützter Chatbot. In der Praxis könnten Unternehmen durch gut integrierte ML-Modelle für z. B. Nachfrageprognosen, personalisierte Empfehlungen oder Fraud Detection eine deutlich höhere Wertschöpfung erzielen. Generell lässt sich sagen: ML macht einen großen Teil der KI-Umsätze aus, besonders in:
ML-Software (Tools, Frameworks, Cloud-ML-Services)
ML-as-a-Service (MLaaS) (z. B. AWS SageMaker, Google Vertex AI)
Industrielle Anwendungen (Predictive Maintenance, autonome Systeme)
Ohne das richtige Bewusstsein und die entsprechenden Kompetenzen bleibt die Wahrnehmung meist auf „GPT = KI“ beschränkt.
Vielleicht bietet diese Artikelserie einen Einblick in das Thema, welcher aufzeigt, welche Relevanz Machine Learning wirklich hat.
Die Motivation
Warum die Mühe, warum diese Serien von Posts?
Um die Motive zu erläutern, bedarf es einer längeren Geschichte. Kybernetik - Regelkreise - in der Produktionsplanung und -steuerung war eines der zentralen Themen meines Studiums, nämlich meiner damaligen Diplomarbeit Ende der 80-er Jahre im Bereich der Wirtschaftsinformatik.
Die zentrale Fragestellung war: Wie kann man Software entwerfen, welche sich auf Basis von bestimmten Zuständen und Ereignissen auf den verschiedenen Planungsebene quasi selbst aussteuert. Eine Software, die auf der Basis von Feedback- und Feedforward-Kontrolle automatisch unvorhersehbare Umweltzustände adaptiert und mehrstufige Regelungsebenen (strategische Planung → operative Steuerung → Maschinenebene) integriert.
Vor mehr als 15 Jahren bewegte in einigen MES-Projekten im Kontext Industrie 4.0 die Frage: Was machen wir mit all den Sensordaten. Ich war in MES-Projekten des Anlagenbaus leitend involviert. Innerhalb dieser Projekte bewertete man kundenseitig die riesige Datenmenge, deren Speicherung und rudimentäre Auswertung als interessant, aber weniger als Treiber für Geschäftsmodelle. Damals wurden für den Kunden erste Modelle in Kooperation mit den Studenten der UCLM (Albacete, Spanien) entwickelt - leider rückten diese Themen vor dem Hintergrund des Ressourcenmangels / der Bindung aller Kapazitäten aufgrund von Umsätzen in noch nie dagewesener Höhe in den Hintergrund - Gegenwart war wichtiger als Zukunft.
In einem der späteren Projekte in der Telekommunikation sollten im Kontext des Business Activity Monitoring die Prozesse des Unternehmens überwacht, analysiert und optimiert werden. Der Ansatz einer event-basierten Architektur / Kommunikation lag nahe und mittels zentraler Speicherung aller in den verschiedenen Prozessen entstehenden Events sollten bspw. Fragestellungen wie nach der prognostizierten Laufzeit eines Prozesses ab einer bestimmten Aktivität beantwortet werden.
Aus der Dokumentenarchäologie: die Originalfolien

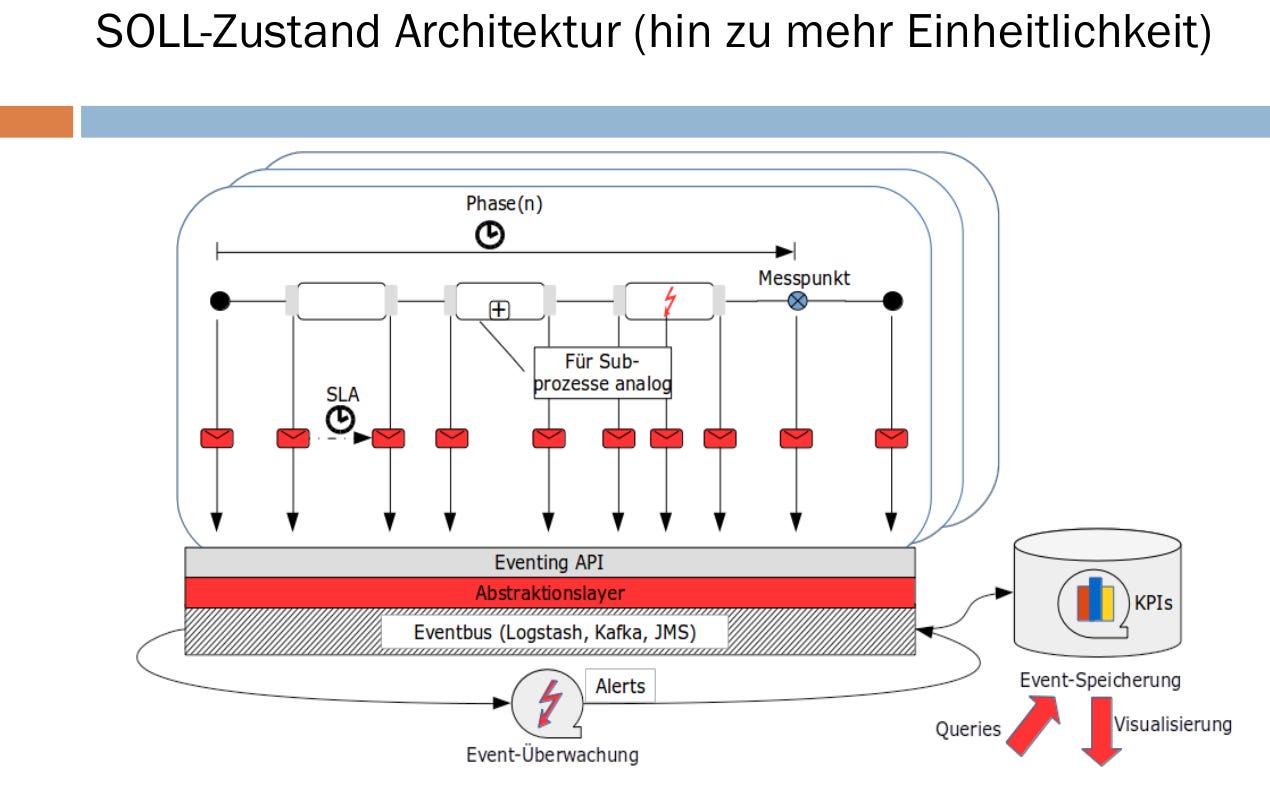
Das Projekt wurde erfolgreich in Betrieb genommen, der Prognoseaspekt aber nie wirklich angegangen. Irgendwie nachvollziehbar war es den Entscheidern wichtiger, den aktuellen Auftragsbestand und den prognostizierten Umsatz anhand einfachster Modelle in Dashboards zu visualisieren. Zusammen mit einem Kollegen wurde ein Promotionsverfahren in diesem Kontext angegangen - der Kollege wollte promovieren, nicht ich - und die Kooperation mit der Rheinischen Hochschule in diesem Themenbereich vertieft.
Wiederum Jahre später und in einem Kontext eines Projektes der öffentlichen Hand tauchten bei der Erstellung eines Blueprints für eine event-basierte Kommunikationsschicht für die einzelnen Systeme des Kunden eben diese Fragestellungen wieder auf.

Die Kooperation mit der Rheinischen Hochschule wurde ausgebaut und die zugrundeliegenden Fragestellungen und Lösungsansätze hierfür als Teil des Weiterbildungsangebots angedacht.

Die Literaturrecheche im Zuge der Ausarbeitung hinterließ den Eindruck, dass es eine Vielzahl von Büchern zu dem Thema gibt; will man jedoch eine projektbezogene Sicht auf die Thematik, dann sind auf einmal gar nicht so viele Bücher, Artikel whatsoever zu finden. Erste, themenbezogene Ausarbeitungen enststanden, nachfolgend wurden die Inseln zusammengefügt und “verschriftlicht“. Dieses bildete die Grundlage für die Blogposts dieser Reihe.
Hier geht es zum Folgeartikel (wirtschaftliche Bedeutung), bleiben Sie mir gewogen.
